Data Virtualisation
Providing unified, controlled access to your data irrespective of its source.
Rarely is it practical to incorporate 100% of the data that needs to be analysed into a single data warehouse and the increase in adoption of Hadoop-based platforms to handle unstructured data (which in its raw form is unsuitable for storage in a conventional data warehouse) exacerbates the problem. It is not unusual to need to run analysis across multiple databases along with information stored in network filesystems or Hadoop platforms.
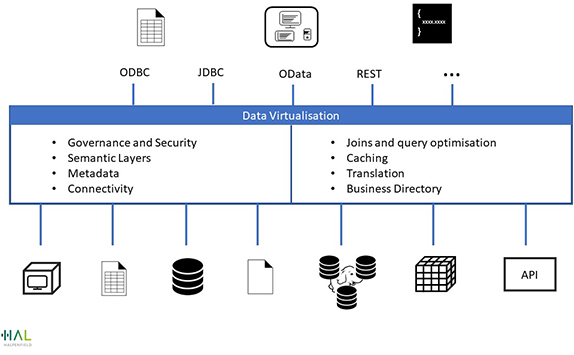
Data Virtualisation is a software layer that sits across all of your data sources (including databases, files, API-accessed data sources and Hadoop systems) in order to federate queries across them and control access to the data within them. The virtualisation software layer knows how to query the underlying data sources in their native language whilst leaving the data in-situ or caching it if appropriate. It can even run queries across data sources, creating joins via the virtualisation layer, and can also apply security centrally thus controlling data access, irrespective of the tool or protocol used to query it.
Get in touch for advice on any of our services