In my blogs I have discussed a variety of topics relating to becoming a data-driven enterprise, including the advantages of adopting a Cloud-first approach, escaping from Excel hell, data warehouses and data lakes. In this blog we will bring these together by considering the components of a modern data architecture and the data journey through it.
In my blogs I have discussed a variety of topics relating to becoming a data-driven enterprise, including the advantages of adopting a Cloud-first approach, escaping from Excel hell, data warehouses and data lakes. In this blog we will bring these together by considering the components of a modern data architecture and the data journey through it.
There are a number of factors driving the requirement for a modern approach to data architecture including:
- Increasing volumes of data
- Increasing variety of data sources
- Increasing use of analysis and insight around the business
- The requirement for low information latency (minutes not days)
- The ability to access information anywhere
- A desire to reduce the cost of ownership of IT infrastructure
- The requirement for a rapid time to value
As discussed in a previous blog, many of these are alleviated through the application of technologies that leverage the benefits of the Cloud. Let’s start, therefore, with the premise that a modern data architecture is cloud-based.
There are a number of functional blocks required to implement a data analytics architecture which are best described when considering the data journey:
- First, data needs to be acquired and loaded into the environment where it will be managed and processed (we will save the case of Data Virtualisation for another blog).
- It then needs to be organised in a manner suitable for its intended use.
- Value needs to be derived from it in the form of some sort of analysis or processing.
- That value then needs to be delivered. This can take various forms including visualisation, providing an input to another process or by sharing information (usually via an API or data extract).
The schematic outlines the components of a modern data architecture and we will consider each in turn: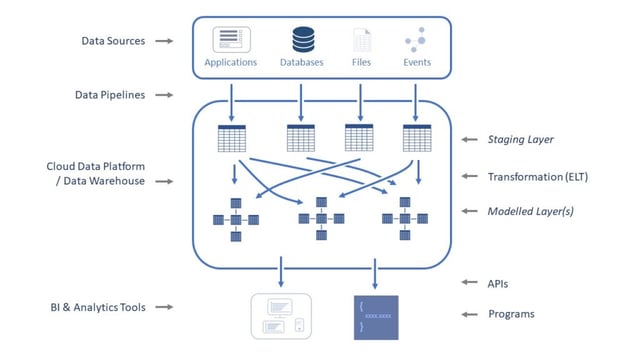
Data Sources – as already mentioned, the number and variety of data sources continues to expand. Typically, data needs to be incorporated from databases, file-based sources (including Excel and semi-structured data such as XML, JSON and AVRO) and both on-premise and cloud-based applications, which are often accessed via an API.
Data Pipeline – the fundamental task of a data pipeline is to move data as efficiently as possible from source to destination. Modern data pipeline tools (most of which are cloud-based) take this a step further by providing intelligent connectors into all of the data source types mentioned above; including an increasingly large number of application APIs. Data pipeline tools can perform an initial data load but also provide Change Data Capture, whereby changes in the underlying data source are detected and replicated to the data warehouse. Changes in the source schema are also replicated, thus alleviating a significant problem with traditional architectures i.e. propagating schema changes throughout the various stages of processing.
Cloud Data Warehouse or Snowflake Data Cloud – depending upon the technology used, this provides a number of services, including storage, security, processing and publishing data. I won’t repeat the advantages of using cloud-native technologies for this, but the data journey within the platform in a modern data architecture has two main components:
Staging Area – The data pipeline intelligent connectors are aware of, or can discover, how data is organised within the source system and can auto-generate a matching schema in a staging area of the data warehouse. The purpose of this staging schema is purely to accept data from the source, it is not optimised for any other purpose at this point and in this respect, it often replaces the requirement for a separate data lake, where structured and semi-structured data is concerned.
This staging area contains raw, or unprocessed data, and is often the ideal source of data for analysts using data discovery and analytics tools who want to explore and derive insight.
Modelled Layer (Data Warehouse, Data Marts or Modelling Tables) – most consumers of data are not analysts, however, and in order to make it easily accessible within visualisation and business intelligence tools, data must be converted using business rules into what we understand as data warehouse or data mart structures. This is done using transformation tools, as described next.
Data extracted directly from transactional systems also needs transformation before it is suitable for advanced analytics techniques, such as predictive or descriptive modelling. This leads to a very different schema to that used for business intelligence, i.e. modelling tables, but it is appropriate to mention it here.
Transformation (ETL vs ELT) – in a modern data architecture, transformation takes place between the staging area and the modelled layer. Traditionally, data transformation would have been done with Extract Transform and Load (ETL) tools, usually between the source and the data warehouse. These extract the data that is to be transformed into their own environment, manipulate it and then load it into the data warehouse. The major advantage of ETL tools is that they offer a means of managing transformation logic through a graphical interface and independent of the database platform itself. This approach does, however, often introduce performance issues.
The alternative is to code transformation logic within the database itself, either via a collection of SQL scripts or using stored procedures written in semi-proprietary languages such as Oracle’s PL-SQL or Sybase’s T-SQL, which Microsoft went on to develop its own dialect of.
The advantages of this approach is that data movement is minimised and stored procedures (which run as compiled code in the database engine) are fast if the database platform has sufficient processing power to support the workload. No ETL-style graphical interface here, though, and any DBA who has had to maintain a large number of transformation routines, whether in stored procedures or a collection of SQL scripts, knows of the administrative overhead this entails.
Extract Load Transform (ELT) tools combine the graphical user interface approach of an ETL tool with the advantages of in-database processing. This is particularly pertinent with an elastic cloud data warehouse technology, such as Snowflake, as processing power can be dedicated to ELT activities and scaled up and down as required. An ELT tool does not load the data into its own environment but rather it generates SQL code to be run within the database in order to perform the transformations.
To head-off any confusion, I would urge you not to get hung-up on the terminology of ELT; for the purposes of this discussion we are focusing on the T and whether it is performed inside or outside of the data warehouse itself.
BI and Analytics Tools – there is no inherent value in storing data, it is what you do with it that provides the value. This is not the place to discuss the applications of data, or the tools available to perform dashboarding, reporting or advanced analytics. Suffice it to say, that a modern data architecture provides support for the widest range of tools and systems by making access available via a variety of means; including long established interfaces such as ODBC and JDBC, as well as providing controlled data services via industry-standard APIs such as SOAP, and REST. In addition to this, data is often exported into files for sharing with third parties and Snowflake has come up with an innovative way of securely sharing data – more on this in a later blog.
This is an architecture that SDG Group implements on a regular basis. Leveraging cloud technologies, the time to value can be a fraction of that of preceding approaches and the elasticity of cloud platforms means that it is no longer necessary to scale for your peak load and then have your system running at a fraction of its capacity for most of the time. It is difficult to understand how simple data pipelines make data loading until you have tried them and using ELT, as opposed ETL, means that it is not necessary to move large amounts of data simply to transform it.
Next we will discuss an increasingly common use of data i.e. sharing it with third parties.

We help companies to create data-strategies & roadmaps,
design and implement cloud data & analytics architectures
and incorporate data governance solutions.